MISC-Write-Up-Zh
As a routine notepad to record some recurrent tasks in Chinese.
These tasks are somewhat special or interesting, which deserve recording.
[2022首届数据安全大赛]SQLPacket
SQLPacket.1
题干信息:

解题:

追踪的路径:
- 协议分级,定位
http - 查看对象,
HTTP,发现存在cmd=ls等信息 - 过滤数据,
http contains "cmd=ls" - 右击过滤HTTP流
- 发现
secret1687456.txt
SQLPacket.2
题干信息:

解密:

- url解码
- base64解密
得到如下信息:

可得,密钥为05c1cc9c2deafb75,采用AES128加密。
到tq 197。

- AES解密
- base64解码
得到如下信息:

追踪HTTP流,使用返回包进行求解。

直接在notepad++中进行转换
- base64解码
- hex -> ascii 转换

从而得到secret1,即为ae1690a2-8e67-421e-bdcd-c4510995da98。
[2022首届数据安全大赛]账密泄密追踪

账密泄密追踪.1
题干信息:

解题:
直接在GitHub上搜索green berry。

进入项目中,使用泄露的五个账号依次查找,从而找到了泄露文件位置。

该url为https://github.com/Tristan-Hao/Green-Berry/blob/main/scrubbers.py。
账密泄密追踪.2
题干信息:

解题:
因为在gitee平台,利用qingmei进行查找,发现该项目。

进入项目,进行查找。

该url为https://gitee.com/datasecurity-qunzhong/qing-mei-login/blob/master/scrubbers.py。
账密泄密追踪.3
题干信息:

解题:
凡是还得登录以及必须手机号注册的东西,我告辞。
网上截图。

以及识别url后得到https://www.yuque.com/shuanxiaoming/gsx1eb/efnpu3。
账密泄密追踪.4
题干信息:

解密:

得到泄露url,https://zhuanlan.zhihu.com/p/521587651。
账密泄露追踪.5
题干信息:

解题:
在CSDN上,利用关键词青莓进行查找。



得到两个泄露url。
[2022首届数据安全大赛]泄露溯源定位

泄露溯源定位.1
题干信息:

解题:

这个流相对较大,再加上察觉到mysql的授权以及查看到后续存在隐私信息,所以基本定位该流为关键流。

所以定位该用户应该为dataUser3。
泄露溯源定位.2
题干信息:

解题:

点进去得到网址:
https://github.com/Tristan-Hao/Green-Berry/blob/f766064e4f9c38bf4aefa06fd3d4abbda7fe4914/catalogue.py
所以提交即可。
泄露溯源定位.3
题干信息:

解题:

如果无法定位具体使用的数值是什么,那回归数据包进行查看。利用详情界面的值当作密文进行解密。

根据密文判断采用的解密类型,发现应当是AES,且密钥是aa01。




根据解密之后得到的信息可以发现,除了姓名,电话以外,还有地址,银行账号以及邮箱地址也被泄露了,即ADE。
[qwb2022]谍影重重
- Route.pcapng
- config.json
- Amazing.zip
Amazing.zip为加密压缩包,加密文件为flag,基本判断通过其他两个文件得到压缩包的解压密码。打开压缩包也得到了明确的提示。

vmess协议
[协议细节 - VMess 协议 - 《Project V(V2RAY)文档手册》 - 书栈网 · BookStack](https://www.bookstack.cn/read/V2RAY/developer-protocols-vmess.md#VMess 协议)
v2fly/v2ray-core: A platform for building proxies to bypass network restrictions. (github.com)
主要就是看手册分析协议内容,根据协议定义进行计算。
时刻注意调用函数的格式,是字符串还是字节!本题基本都是字节。
协议初始定义

计算cmd_key以及cmd_iv
根据协议,先把指令部分求解出来。

我们的用户ID在config.json中体现。
1 | "settings": { |
使用匿名函数lambda把一些本题的常用函数给定义一下,简化调用步骤。
1 | md5 = lambda x: hashlib.md5(x).hexdigest() |
可以从协议定义来看,关键点在M之上。所以我们需要利用hmac值,爆破出关键的时间点M。
但这一步莫名其妙一直没成功,无法爆出需要的时间,所以还有待改进中。不是python版本问题。
根据协议提示,写获取M的函数。
1 | # 理论上 |
p64()在pwntools库中,需要进行安装。
前置条件,需要找到进行响应的数据包基本条件:时间较早;数据量较大;存在数据。

大概的时间范围,以该流量包中的时间进行时间戳的转换。


找到参照时间戳为1615528962。
1 | import hmac |
对指令部分进行解密

根据协议手册,我们了解指令部分各字节的所属以及作用。需要注意的是,我们在此解密的数据是指令数据。
同样的,先利用匿名函数定义所要使用的AES-128-CFB。
1 | cmd_aes = lambda: AES.new(bytes.fromhex(cmd_key), AES.MODE_CFB, bytes.fromhex(cmd_iv), segment_size=128) |
这边得高亮一下,python3中对称密码的使用非常麻烦,因为主要处理的数据都是字节形式,此处注意,不能直接使用b’’来进行转换,会导致长度错误,必须使用bytes.fromhex()进行转换。
AES-128的密钥长度必须为16字节,而b’’转换成字节是32字节,所以会导致报错。
校验F部分,使用FNV1a hash。

1 | from fnvhash import fnv1a_32 |
输出得到:
1 | ver = 01 |
根据协议协定信息进行解密
切分后得到的协议信息,比较关键的部分主要在dat_iv、dat_key、opt以及sec中。

但通过文档发现Opt略显不对,主要因为文档年久失修:)
v2ray-core/headers.go at 5dffca84234a74da9e8174f1e0b0af3dfb2a58ce · v2ray/v2ray-core (github.com)

所以Opt部分,主要开启了GlobalPadding、ChunkMasking以及ChunkStream,所以我们得到信息,元数据开启了数据混淆,所以我们客户端和服务端分别需要构造两个Shake实例。并且解密的时候注意Padding。

而sec部分,也不出意外的年久失修了:)
sec=3的情况下,我们应该选择AES-128-GCM进行解密。


1 | from Crypto.Hash import SHAKE128 |
得到输出:
1 | dat_iv = 5e4a9aa9ba58c7e3ad36fe2499dca259 |
将所有响应数据进行解密
插播,前面都是请求数据,本部分为响应数据。

响应数据依旧使用AES-128-CFB进行解密。
响应数据我们如何得到?直接利用Wireshark追踪数据流功能进行查看。先转换成原始数据,再把所有蓝色数据导出即可。保存为res.bytes。

依旧根据协议定义对解密后的数据进行切分提取。
1 | res = open('res.bytes', 'rb').read() |
输出得到:
1 | res_key = b22984cda4143a919b5b6de8121b6159 |
解密之后所得文件
解密所得文件为一个 html 文件,其中以 base64 编码存放有一份宏病毒。因此这里取出其内容,实测电脑中的杀毒软件对此病毒十分敏感,一旦落入文件系统文件立刻会被损坏,最后为了查看内容直接存储为 zip 文件解压后查看。
1 | from base64 import b64decode |
这一步,如此如此这般这般就得到html文件,并且为宏病毒文件。暂且缘由不太理解,先放着。

利用病毒sha256值反向查找
把zip文件直接放foremost分析一下,能够得到病毒的dll。
1 | $ sha256sum 00000277.dll |

检索得到:Malware analysis extracted_at_0x22a7b.exe Malicious activity | ANY.RUN - Malware Sandbox Online

得到api的url为http://api.ipify.org
md5得到压缩密码为08229f4052dde89671134f1784bed2d6
得到flag文件。
go文件
得到的文件使用WINHEX打开一下,发现提示了文件类型,是Gob文件

利用属性来进行定义,从而反序列化。

导包的时候出现了missing path,找了报错原因,没解决,后来发现是因为格式错了。
1 | import ( |
然后脚本的原理暂且还不太理解,先放着。
1 | package main |
得到图片。

图片隐写
搞出一张图片了,但没明白为啥图片的大小就是70450bytes,有点迷惑。

没找到合适的工具提取隐写,十有八九是提取像素点的。
1 | from PIL import Image |
最后得到flag{898161df-fabf-4757-82b6-ffe407c69475}
[qwb-2021]threebody
stegsolve查看发现图片
你们都是虫子。
放大发现像素点数
相邻像素点数值相差较大。

仔细观察发现如果以4为周期相差像素点数值将相差不大。 -> 修改像素点所占比特数biBitCount 24 -> 32

得到真实图片。

再使用solvesolve进行分析
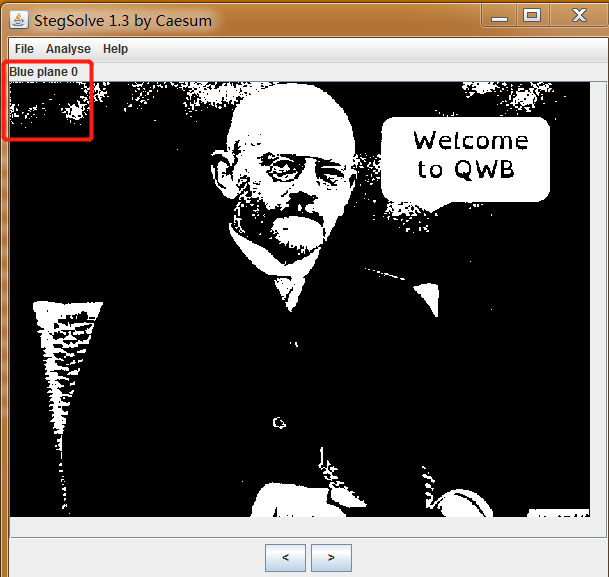
stegsolve进行提取。行列都存在隐写数据。

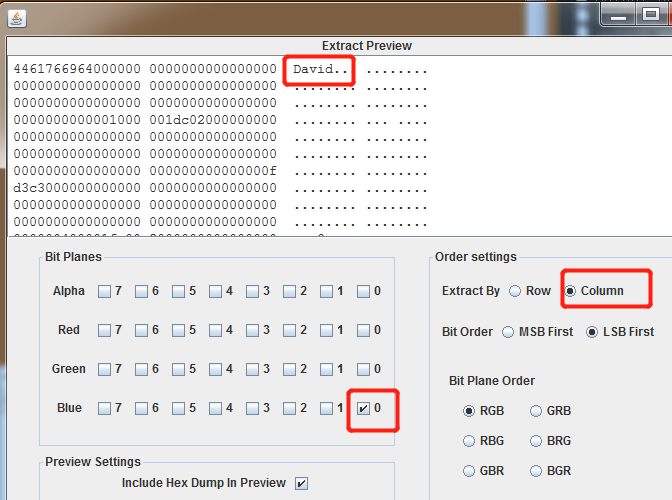
可得提示希尔伯特曲线
冗余数据赋值
观察图片发现存在rgbReserved的字段,表示stegsolve还存在无法识别的通道。
两种方法。
bmp转化成pngblue通道跟Reserved通道大小相近,直接暴力赋值
bmp转化成png
1 | from PIL import Image |
暴力赋值
1 | with open('threebody.bmp', 'rb') as f: |
希尔伯特曲线
1 | import numpy as np |
但这个一直没能实现,不清楚是不是没剪切图片的原因。
0228,笑死,真的是因为没剪切的原因。
C语言编译
打开output.txt发现是C语言脚本,所以用VSCode进行编译运行,发现打印的是自身。
出题人的知识点:
这种可以打印自身的程序学名叫Quine
即使看似是相同的文件,可能存在某种差异,直接用BCompare4对原始文件以及输出文件进行对比,发现在文件的第11行存在差别。
原始文件存在Tab以及Space,转化成01数据流。

用Notepad++得到01数据流。
1 | 01100110011011000110000101100111011110110100010000110001011011010100010101101110001101010110100100110000011011100100000101101100010111110101000001110010001100000011011000110001011001010110110101111101 |
数据处理
1 | output = '2009092020090920200909200909202020090920202020092009092020090909200909090920090920092020200920202020090920202009200909200909200920092020200920092009092009090920202009092009200920090920092020092020090920202020200909200909092020092020202020092009092009092020200920090909090920092009202020202009090920200920202009092020202020200909200909202020090920202009200909202009200920090920090920092009090909092009' |
[护网杯2018]easy_dump
利用vol查看镜像信息
vol.py -f easy_dump.img imageinfo
一般以镜像前1,2个操作系统为分析重点,eg: Win7SP1x64
指定镜像进行进程扫描
vol.py -f easy_dump.img --profile=WinSP1x64 pslist
vol.py -f easy_dump.img --profile=WinSP1x64 pstree
vol.py -f easy_dump.img --profile=WinSP1x64 psscan

发现可疑进程notepad.exe,那么我们直接把记事本内容给提取出来。
记事本内容dump
vol.py -f easy_dump.img --profile=Win7SP1x64 memdump -p 2616 -D ./

把记事本内容dump出来,利用string-grep对dmp文件内容进行检索。
记事本内容直接搜索
strings -eb 2616.dmp | grep flag

-el 也适用, -u相关用法不太不清楚具体案例,从而得到提示,找jpg文件。
根据提示查找图片并导出
vol.py -f easy_dump.img --profile=Win7SP1x64 filescan | grep .jpg

grep进行过滤,也可用其他形式进行检索,主体包含jpg即可。
vol.py -f easy_dump.img --profile=Win7SP1x64 dumpfiles -Q 0x000000002408c460 -D ./

直接导出的就是file:xxxx的格式,我们直接按照需求把文件改成原始文件名即可,eg: phos.jpg
图片隐写分析
有图片就回归到图片方面的隐写分析之上。
binwalk分析,发现存在zip,那么直接对其进行foremost提取。

提取出来一个message.img。
再次进行提取操作,本次使用binwalk -e 进行提取hint.txt。
使用foremost无法分离出来hint.txt文件
生成二维码
gnuplot转换
1 | gnuplot |
然后直接输出二维码图片
- 脚本转换 暂且没成功…… -> 成功了,原终端为agg,无图形界面,需要切换为图形界面显示的终端TkAgg
1 | import matplotlib.pyplot as plt |
扫描即可得到信息:1. 维吉尼亚密钥为aeolus 2. 加密后的密文被删除了
恢复镜像删除信息
使用testdisk进行恢复:testdisk message.img,进入相应的操作界面。

进入Proceed。

进入None。

因为涉及删除的文件,所以直接找该功能模块Undelete。

找到标红处,说明该处存在删除文件。

按c确定文件以及路径之后,出现该红框内内容说明导出成功。

到保存路径之下,使用ls -a发现保存下来的文件,直接利用strings查找字符串即可。

找到加密后的密文,使用在线解密网站结合密钥解密即可,最终得到相应的flag。
[国赛]everlasting_night
利用stegsolve得到隐藏密钥
- stegsolve导入图片,通过下方左右箭头进行查看,发现alpha 2通道右下角存在列向隐藏数据

- 选项卡
Analyse的下拉列表选择Data Extract,得到f78dcd383f1b574b

!在靠近最下边,稍微仔细查看
cloacked-pixel提取lsb隐写文件
使用条件:
- 存在lsb隐写
- 得到密钥
- stegsolve无法提取lsb隐写文件+得到密钥,考虑另一种带密钥的lsb隐写,即
cloacked-pixel
1 | # python2实现 |
- 把图片放到
cloacked-pixel路径之下,命令行输入python2 lsb.py extract 1.png flag.txt f78dcd383f1b574b

- 打开
flag.txt,发现可能是zip,修改后缀名,得到flag.zip。

- 解压缩,发现需要解压密钥,用winhex判断一下,发现应当是真加密。



winhex通过png文件尾得到一段MD5密文并解密
PNG (png):
文件头:89504E47文件尾:AE426082
- Winhex导入图片,选择左上角选项卡
搜索,下拉框选择查找十六进制数据,输入png文件尾AE426082

- 发现png文件结束后,存在一段密文
FB3EFCE4CEAC2F5445C7AE17E3E969AB

- 因为是32位的16进制字符串,一般先考虑是否是MD5密文,经过解密,得到一段密钥
ohhWh04m1
cmd5.com无法解出。

- 利用该密钥对
flag.zip进行解压缩得到flag
gimp打开图片并进行爆破
gimp为kali的PS处理软件
- 得到
flag,winhex查看发现是应当是png文件,但修改后缀名发现无法打开 - 修改
flag后缀名为.data,输入命令行gimp flag.data

- 发现图片需要处理,图形内容扭曲,一般考虑是高度不变,宽度改变。经过试验,宽度应当为
352

- 得到
flag{607f41da-e849-4c0b-8867-1b3c74536cc4}
[国赛]ez_usb
使用tshark对流量进行处理
winhex转换所得数据
Wireshark对流量包进行分组
usb.addr == “2.x.1”
usb.device_address == 4/8/10
- 分析流量包,发现host为2.10/4/8对应的infoURB_INTERRUPT,设置过滤规则,选中并导出相应的pcapng
1 | usb.device_address == 4/8/10 |

- 分离好不同的流量包使用tshark对流量包数据进行处理
1 | tshark -r 2_x.pcapng -T fields -e usbhid.data | sed '/^\s*$/d' > usb_x.txt |

- 继续处理数据,利用脚本加上
:,分别导出文件output_x.txt
1 | f=open('usb_10.txt','r') |
使用键盘流量相关脚本对txt文件进行处理
1 | normalKeys = { |
分别对三个文本进行处理,最后2_4没跑出数据,2_8/2_10跑出数据

16进制/已知文件头将输出数据转换为压缩包,并解密
- 16进制转换

- winhex

- 生成压缩包后,解压,使用所得密钥
35c535765e50074a进行解密,得到flag{20de17cc-d2c1-4b61-bebd-41159ed7172d}
[国赛]pikalang
stegsolve对pika.png进行通道检查

- 提取出来的数据进行base64解密,得到
pikalang密文

1 | cGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGlrYSBwaXBpIHBpIHBpcGkgcGkgcGkgcGkgcGlwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaXBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpY2h1IHBpY2h1IHBpY2h1IHBpY2h1IGthIGNodSBwaXBpIHBpcGkgcGlwaSBwaXBpIHBpIHBpIHBpa2FjaHUgcGkgcGkgcGkgcGkgcGkgcGkgcGlrYWNodSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBwaWthY2h1IHBpIHBpIHBpIHBpIHBpIHBpIHBpa2FjaHUgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGkgcGlrYWNodSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBrYSBwaWthY2h1IHBpY2h1IGthIGthIGthIGthIGthIGthIGthIGthIGthIGthIGthIGthIGthIGthIGthIGthIHBpa2FjaHUga2Ega2Ega2Ega2EgcGlrYWNodSBwaSBwaSBwaWthY2h1IHBpIHBpIHBpa2FjaHUgcGlwaSBwaWthY2h1IHBpY2h1IGthIGthIGthIGthIGthIHBpa2FjaHUgcGlwaSBwaSBwaSBwaWthY2h1IHBpY2h1IHBpIHBpIHBpIHBpa2FjaHUga2Ega2Ega2EgcGlrYWNodSBwaXBpIHBpa2FjaHUga2Ega2Ega2Ega2Ega2EgcGlrYWNodSBwaSBwaSBwaSBwaWthY2h1IHBpY2h1IGthIHBpa2FjaHUgcGkgcGkgcGkgcGlrYWNodSBrYSBwaWthY2h1IHBpcGkgcGkgcGlrYWNodSBwaWthY2h1IHBpY2h1IHBpIHBpa2FjaHUga2Ega2Ega2EgcGlrYWNodSBwaSBwaWthY2h1IHBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpa2FjaHUga2Ega2Ega2Ega2Ega2Ega2EgcGlrYWNodSBwaXBpIHBpIHBpa2FjaHUgcGljaHUgcGlrYWNodSBwaXBpIGthIGthIGthIGthIGthIHBpa2FjaHUgcGkgcGkgcGkgcGkgcGkgcGlrYWNodSBwaWNodSBrYSBrYSBwaWthY2h1IHBpIHBpIHBpIHBpIHBpa2FjaHUga2EgcGlrYWNodSBrYSBrYSBrYSBrYSBwaWthY2h1IHBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpIHBpa2FjaHUgcGlwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaSBwaWthY2h1IA== |
- 引入第三方库
pikalang,最后使用pokeball编写脚本
1 | # import pikalang |
[网鼎杯 2020 青龙组]虚幻2
解压缩得到
filetools:
- winhex
- 中国编码APP
- pycharm
hint:
- 汉信码
- 爆破
- 使用
winhex发现文件头是PNG,所以把后缀名修改,得到file.png - 将
file.png进行读取,得到01字符串
1 | # 读取像素点 |
- 将
01字符串写入图片,得到缺失一块的汉信码。
1 | # 写入成为图片 |

- 稍微补充点,然后让汉信码自动校正。得到
flag{eed70c7d-e530-49ba-ad45-80fdb7872e0a}
电子数据取证-Volatility
1. Suspicion
解压缩得到mem.vmem suspious
tools:
- vol.py
- Elcomsoft Forensic Disk Decryptor(EFDD)
- 通过
vol.py -f mem.vmem imageinfo获得基本信息

- 通过
vol.py -f mem.vmem --profile=WinXPSP2x86 pstree,得到加密进程TrueCrypt.exe,推断suspious是加密后的数据

- 通过
vol.py -f mem.vmem --profile=WinXPSP2x86 memdump -p 2012 -D ./(-p为PID,-D是转储路径)

- 使用
EFDD对2012.dmp进行解密以及挂载。





进行挂载操作。

- 查看挂载后的数据,找到
PCTF{T2reCrypt_15_N07_S3cu2e}

2. [湖湘杯2020] passwd
解压缩得到
WIN-BU6IJ7FI9RU-20190927-152050.rawMD5解密
- 依旧查看基本信息
vol.py -f WIN-BU6IJ7FI9RU-20190927-152050.raw imageinfo

- 查看hash值
vol.py -f WIN-BU6IJ7FI9RU-20190927-152050.raw --profile=Win7SP1x86_23418 hashdump

- 使用MD5网站进行解密,得到
qwer1234

3. [NEWSCTF2021] very-ez-dump
解压缩得到
mem.raw
- 查看镜像信息
vol.py -f mem.raw imageinfo

- 查看cmd所执行的相关命令,发现添加了一个用户
mumuzi且密码为(ljmmz)ovo

- 查找flag关键词
vol.py -f mem.raw --profile=Win7SP1x64 filescan | grep flag,发现flag.zip进行转储vol.py -f mem.raw --profile=Win7SP1x64 dumpfiles -Q 0x000000003e4b2070 -D ./(-Q为地址,-D为转储路径)

- 用
winhex发现应该是zip,修改后缀名,发现压缩包进行真加密,并且需要相应的密码。

- 用2中得到的密码对压缩包进行解密,最后解密得到
flag{ez_di_imp_1t_y0u_like?}
5. [HDCTF2019]你能发现什么蛛丝马迹吗
解压缩得到
memory.imgtools:
- volatility
- 正常流程,先看具体里面内容
vol.py -f memory.img imageinfo

主要使用了Win2003SP,根据尝试,发现Win2003SP0x86无法读取相关的数据,所以主要选择Win2003SP1x86等进行内存取证。
- 使用
vol.py -f memory.img --profile=Win2003SP1x86 sptree查看进程。发现两个可疑进程ctfmoon.exe和DumpIt.exe,ctfmoon.exe进程相对久远,优先查看DumpIt.exe。

DumpIt.exe主要是用来内存取证的工具,那主要的思路就是查看它主要做了哪些工作。
- 使用
screenshot查看vol.py -f memory.img --profile=Win2003SP1x86 screenshot --dump-dir=./

- 发现了
flag.png,此时主要查找相关的flagvol.py -f memory.img --profile=Win2003SP1x86 filescan | grep flag

vol.py -f memory.img --profile=Win2003SP1x86 dumpfiles -Q 0x000000000484f900 -D ./ -u
把flag相关给导入数据,最后得到00.dat。
二维码扫一扫发现一段疑似base64密文。但解密没得到有用数据,于是继续从别的渠道查看。
- 查看打开了哪些软件以及具体操作
vol.py -f memory.img --profile=Win2003SP1x86 windows

Pid:1992,使用图片和传真查看器查看了flag.png。
然后我们把这些相关数据给导出
vol.py -f memory.img --profile=Win2003SP1x86 memdump -p 1992 -D ./,从而得到1992.dmp我们得到
1992.dmp后,利用foremost 1992.dmp把隐藏其中的相关数据给导出


里面发现这些图片。
二维码就是之前分离出来的,扫出来是jfXvUoypb8p3zvmPks8kJ5Kt0vmEw0xUZyRGOicraY4=,而另一张图显示key:Th1s_1s_K3y00000以及iv:1234567890123456。出现IV+密文也是base64形式。所以考虑是否进行了AES加密。
- 对密文进行AES解密,因为告诉了IV所以主要考虑是不是除了ECB以外的模式,但最终其实就是ECB模式的AES解密。(所以这一步很迷,给的IV难道就只是提示AES?)
AES解密:在线AES加密解密、AES在线加密解密、AES encryption and decryption–查错网 (chacuo.net)

最后得到密文flag{F0uNd_s0m3th1ng_1n_M3mory}